
데이터에 결측값이 있을 경우 데이터 분석을 하기 위해 처리하는 전략은 크게 3가지가 있다.
- 무시하기
- 제거하기
- 다른 값으로 대체하기
첫 번째 무시하기는 그냥 무시하고 진행하면 된다.
제거와 대체하는 방법에 대해 알아보자.
items2 = [{'bikes': 20, 'pants': 30, 'watches': 35, 'shirts': 15, 'shoes':8, 'suits':45},
{'watches': 10, 'glasses': 50, 'bikes': 15, 'pants':5, 'shirts': 2, 'shoes':5, 'suits':7},
{'bikes': 20, 'pants': 30, 'watches': 35, 'glasses': 4, 'shoes':10}]
import pandas as pd
df = pd.DataFrame(data= items2, index= ['store1', 'store2', 'store3'])
먼저 비어있는 데이터가 어디에, 몇개나 있는지 파악해야 한다.
df.isna() 또는 df.isnull() 함수는 데이터가 있으면 True, 없으면 False를 리턴한다.
df.isna()
df.notna() # isna() 함수의 반대
df.isna() 에 sum()을 하면 NaN이 몇개인지 알 수 있다.
df.isna().sum()
>>> bikes 0
pants 0
watches 0
shirts 1
shoes 0
suits 1
glasses 1
dtype: int64
df.isna().sum().sum() # 전체 데이터의 NaN 갯수
>>> 3
df.dropna()
결측값을 제거한다.
파라미터에 how와 axis가 있는데
how= 'any' 일 때는, 하나라도 결측값이 존재한다면 그 결측값이 존재하는 행 or 열을 제거하고
how= 'all' 이면 행 or 열에 있는 모든 값이 NaN인 경우에만 제거한다.
그리고 axis= 0일 때는 행, axis= 1 일때는 열을 제거한다.
디폴트 파라미터는 how= 'any', axis=0 이다.
df.dropna() # 널값이 포함된 행 삭제
# = df.dropna(how='any', axis=0)
df.fillna()
결측값을 특정값으로 대체한다.
# 0으로 대체한다.
df.fillna(0)
# suits 와 glasses의 비어있는 데이터는 100으로 채운다.
df[ ['suits', 'glasses'] ] = df[ ['suits', 'glasses'] ].fillna(100)
# 위 행의 데이터로 대체한다
df.fillna( method='ffill', axis=0 )
# 아래 행의 데이터로 대체한다
df.fillna( method='bfill', axis=0 )
# 왼쪽 열의 데이터로 대체한다
df.fillna( method='ffill', axis=1 )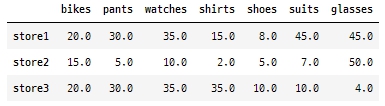
# 오른쪽 열의 데이터로 대체한다
df.fillna( method='bfill', axis=1 )
# 컬럼의 평균으로 대체한다
df.fillna(df.mean())
'Python > Pandas' 카테고리의 다른 글
| Pandas 활용(7) - 함수의 일괄 적용 apply (0) | 2022.11.28 |
|---|---|
| Pandas 활용(6) - 범주로 묶어 집계하기 groupby, agg (0) | 2022.11.27 |
| Pandas 활용(4) - 인덱스명, 컬럼명 변경 (0) | 2022.11.27 |
| Pandas 활용(3) - 데이터프레임의 데이터 변경, 추가, 삭제 (0) | 2022.11.25 |
| Pandas 활용(2) - 데이터프레임의 Indexing, Slicing (0) | 2022.11.25 |