

linear regression 을 이용해 수치예측하는 방법을 알아보겠다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('../data/auto-mpg.csv')
컬럼정보
- mpg : 연비
- cyl : 실린더 갯수
- displ : 배기량
- hp : 마력
- weight : 무게
- accel : 60mph 까지 걸리는 시간
- yr : 연식
- origin : origin of car (1. American, 2. European, 3. Japanese)
# 1. 데이터 파악
df.head()
df.info()
df.describe()
# 2. nan 확인
df.isna().sum()
name 컬럼을 제외한 나머지 데이터들로 연비를 예측하겠다.
# 3. X 와 y로 분리
X = df.loc[ : , 'cyl':'origin']
y = df['mpg']
df['origin'].unique()
df['cyl'].unique()
df['yr'].unique()origin, cyl, yr 컬럼은 카테고리컬 데이터이다.
origin 컬럼은 카테고리가 3개이기 때문에 학습이 더 잘 되도록 원핫인코딩으로 변환해주겠다.
cyl, yr은 수치이기 때문에 학습에 영향을 줄 수 있을 것 같으므로 그대로 둔다.
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
ct = ColumnTransformer( [ ('encoder', OneHotEncoder(), [6]) ],
remainder = 'passthrough')
X = ct.fit_transform(X.values)
# 4. train set, test set 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2 , random_state=1)
# 5. feature scaling
# 여기서 사용할 LinearRegression은 자체적으로 피쳐스케일링을 해주기 떄문에 패스한다.
# 6. linear regression으로 모델링
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
# 학습
regressor.fit(X_train, y_train)regressor.coef_ # 기울기
regressor.intercept_ # 절편
# 7. 예측
y_pred = regressor.predict(X_test)
# 8. MSE로 평가
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, y_pred)
실제값과 예측값이 얼마나 차이 나는지 보기 쉽게 차트로 시각화 해보자.
plt.plot(y_test.values)
plt.plot(y_pred)
plt.legend(['Real', 'Pred'])
plt.show()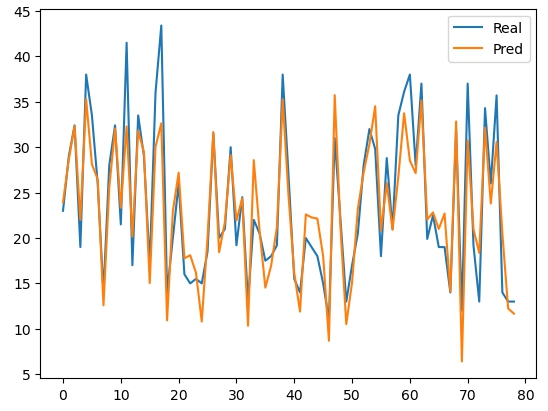
내가 만약 실제로 이 인공지능을 deploy(배포) 하려면,
학습이 완료된 모델을 저장, 불러오기 하고 실제 예측까지 구현해야 한다.
아래 코드로 확인해보자.
# One-Hot encoding column transformer 와 linear regression 모델을 파일로 저장하기
import joblib
joblib.dump(ct, 'ct.pkl')
joblib.dump(regressor, 'regressor.pkl')# 저장한 모델 불러오기
ct2 = joblib.load('ct.pkl')
regressor2 = joblib.load('regressor.pkl')# 새로운 자동차가 나왔습니다.
# displ 301, hp 133, cyl 6, weight 2900, accel 10.7, yr 81, origin2(유럽차)
# 이 차의 연비를 예측해 보세요.
new_car = np.array([6, 301, 133, 2900, 10.7, 81, 2]).reshape(1, -1) # 2차원으로
new_car = ct2.transform(new_car)
regressor2.predict(new_car)'Machine Learning' 카테고리의 다른 글
| 데이터 전처리 - 결측값 처리, 피처 스케일링, train_test_split (0) | 2022.12.05 |
|---|---|
| 데이터 전처리 - Categorical Encoding (0) | 2022.12.05 |